Kaggle - Santander Product Recommendation
www.kaggle.com/c/santander-product-recommendation/overview
사이트의 자료를 보고 정리했습니다.
Santander Product Recommendation 소개
산탄데르 은행은 1857년 지방은행으로 출발해, 급성장 후 유럽과 북남미 등지에 1만4000여 지점과 1억명 이상의 고객을 보유한 자산규모 기준 세계 15위 은행이다.
현재 산탄데르 다양한 금융 상품을 판매하여 매출을 올리는데, 자사의 금융 상품을 사용 중인 고객을 대상으로 아직 고객이 사용하고 있지 않은 다른 금융 상품을 소개하여 만족도를 높임과 동시에 매출을 올리고 싶어 한다.
고객을 만족시킬 수 있는 가장 좋은 상품 추천 방법은 숙련된 직원이 고객의 정보를 바탕으로 자산 계획과 금융 상품을 추천해주는 것인데, 많은 숫자의 직원을 고용하는 것은 불가능에 가깝다. 그래서 매일 은행을 방문하는 고객들 모두에게 1:1 맞춤 금융 상품을 추천하기 위해 머신러닝 알고리즘을 사용하기로 했다.
프로젝트 목적
1) Data Analysis(어떤 일이 어떻게, 왜 일어 났는지 설명하기 위한 분석)
- 자사의 금융 서비스를 이용하는 고객들의 특성 분석
2) Data Analytics(분석을 사용하여 잠재적인 미래 이벤트를 탐색, 패턴 찾기)
- 자사의 고객들을 대상으로 고객 맞춤형 상품 추천을 제공
=> 고객의 과거 이력과 유사한 고객군들의 데이터를 기반으로 다음달에 해당 고객이 무슨 상품을 사용할지 예측
=> 고객의 만족도를 높임과 동시에 은행 매출에 기여
데이터
www.kaggle.com/c/santander-product-recommendation/data
고객이 구매할 신제품을 예측하기 위해 Santander 은행에서 1.5 년 동안의 고객 행동 데이터를 제공
데이터는 2015-01-28에 시작되며 "신용 카드", "저축 계좌"등과 같이 고객이 보유한 제품에 대한 월별 기록
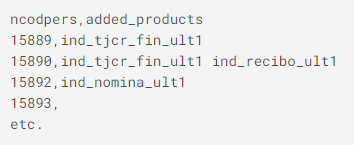
고객이 지난달 2016-에 어떤 추가 제품을 받을지 예측할 수 있고, 2016-05-28에 이미 보유한 것 외에도 06-28. 이러한 제품은 이름이 ind_ (xyz) _ult1이며 훈련 데이터의 # 25-# 48 열입니다. 2016-05-28에 이미 보유한 것 외에 고객이 구매할 제품 을 예측할 수 있습니다.
테스트 및 학습 세트는 시간별로 분할되고 공개 및 비공개 리더 보드 세트는 무작위로 분할됩니다.
참고 : 이 샘플에는 실제 Santander Spain 고객이 포함되어 있지 않으므로 스페인 고객 기반을 대표하지 않는다.
파일 설명
- train.csv- 훈련 세트
- test.csv- 테스트 세트
- sample_submission.csv- 올바른 형식의 샘플 제출 파일
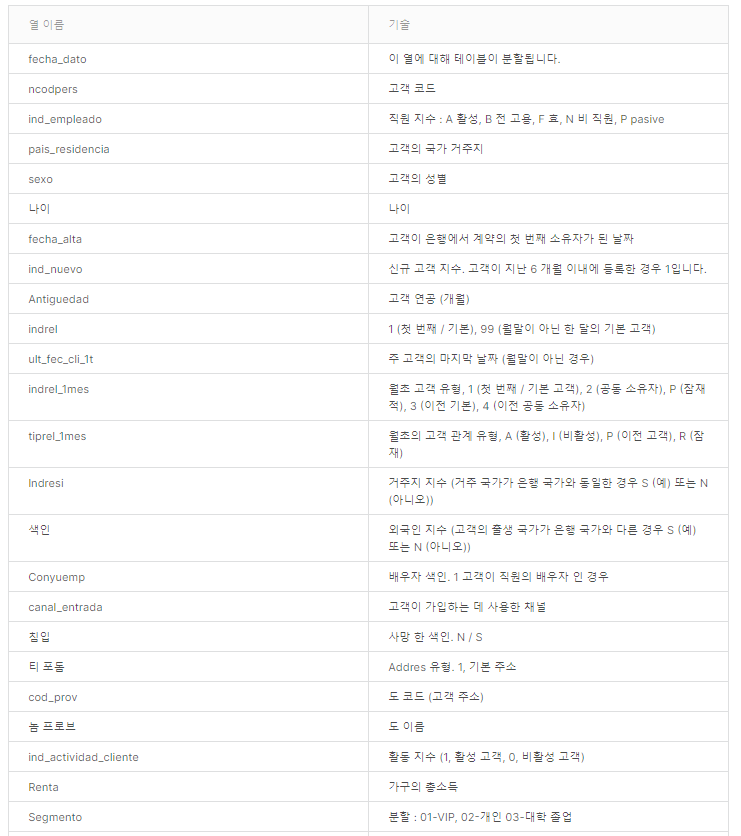
데이터 필드 설명

평가
제출물의 평가는 MAP(평균정밀도)

U는 행 수, P(k)는 컷오프 k에서의 정밀도, n은 예측된 제품의 수, m은 해당 시점 주어진 사용자에 대해 추가된 제품의 수
m=0이면 정밀도는 0으로 정의됨.
제출 파일
각 시점의 모든 사용자에 대해, 공백으로 구분된 제품의 목록을 예측.